The only things certain in life are death, taxes, and your technology stack will change over time. While architectural changes are complicated in their own right, the challenges are even greater when your primary data store is changing to a fundamentally different technology.
A recent project involved migrating applications from a legacy architecture based on Java/Hibernate/Oracle to a new architecture based on Ruby/MongoMapper/MongoDB. In order to facilitate the transition from Oracle to MongoDB, we needed a temporary ETL solution to migrate data from Oracle to MongoDB. A new domain model and document structure had been designed and developed for MongoDB with Ruby/MongoMapper, and there were existing Java/Hibernate entities mapped to Oracle.
Rather than having to re-map one database or the other in the other persistence technology to facilitate the ETL process (not DRY), JRuby allowed the two persistence technologies to interoperate. By utilizing JRuby’s powerful embedding capabilities, we were able to read data out of Oracle via Hibernate and write data to MongoDB via MongoMapper.
Example Domain Model
To demonstrate the RDMBS to MongoDB ETL process, consider the ubiquitous blog domain model.
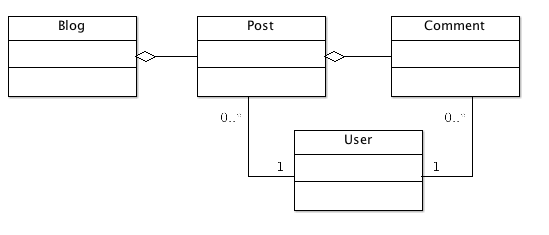
A Blog contains many Posts, and a Post contains many Comments. Users create Posts and Comments. The relational model for this domain model would look something like this:
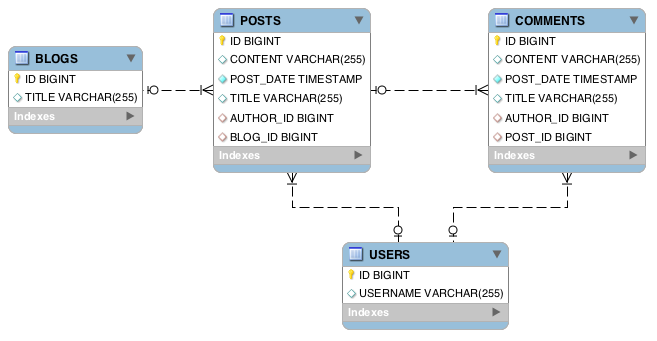
The schema is highly normalized. Entities live in their own tables, and are tied together via foreign keys.
With document databases like MongoDB, you typically want to denormalize data according to your access patterns, as you can’t rely on joins. In our example blog domain model, storing posts and comments in separate collections would result in unnecessary querying. Thus, these will become embedded collections within their respective parent documents, and our resulting Blog MongoDB document would look something like this:
posts is an embedded collection within a blog document, and comments is an embedded collection within a
post document. We denormalize the username of the author of posts/comments, and also store the user’s ObjectId,
which will allow us to generate links like
Posted by <a href="http://myblog.com/users/4f7d0176f1bb3e1223000005">bill</a>
Translators
Translator classes are Ruby classes which translate Java/Hibernate objects to their Ruby/MongoMapper counterparts,
and contain the logic for dealing with denormalization.
Let’s look at an example. The Hibernate domain model class for Blog would look something like this:
Its MongoMapper counterpart would look something like this:
The BlogTranslator class contains the logic to translate Blog entities to Blog documents:
Some things to note:
- Each
Translatoris idempotent and knows whether to create or update the document in MongoDB. We store the RDBMS identifer of the source entity in the MongoDB document to facilitate this logic. Translatorscan call otherTranslatorsas they traverse the Hibernate model’s object graph. Above we see that theBlogTranslatorcalls thePostTranslatorto translate each associated post.- Having each
Translatorbe responsible for a single entity (or logical entity) allows you to plug theTranslatorinto your applications to perform real-time incremental ETL as entities are created/updated, as well as chainTranslatorstogether to create large scale batch sync ETL processes.
Embedding Translators in Java
With the use of JRuby’s ScriptingContainer
class, we can embed our Translator objects into our Java applications to facilitate the ETL process. Suppose we
have a command line app which ETLs all Blog entities. It would embed the BlogTranslator and pass each Blog
Hibernate model object to the BlogTranslator object’s translate method.
Example ETL application
A complete RDBMS -> MongoDB ETL application for our blog domain model can be found here:
https://github.com/bploetz/jruby-etl
The repository contains two main directories: java and ruby.
The java directory contains the Hibernate domain model mapped to the relational database, as well as the
example ETLManager class which demonstrates JRuby’s embedding capability.
The ruby directory is a RubyGem containing the MongoMapper domain model mapped to MongoDB, as well as
the Translator classes.
To run this project the following are required:
- JDK 1.5 or higher
- Maven 2.2
- JRuby (examples below assume JRuby is installed via RVM)
- The Bundler gem installed
- MongoDB running on the default port at localhost
For simplicity, this example application uses HSQLDB for the RDBMS, so there is no need to have a separate RDBMS installed/running. You can obviously change the Spring/Hibernate configuration to use your RDBMS of choice if you so desire.
Clone the jruby-etl git repository and run the following to compile the Java source files and create the distribution:
rvm use jruby
cd java-etl/java
mvn clean package
cd to the distribution directory and load the example seed data into the relational database.
cd target/jruby-etl-1.0.0-SNAPSHOT-bin/bin
./load-seed-data.sh
Finally, run the ETL app to translate the seed data from the relational database to MongoDB.
./etl.sh
The project is configured to log all SQL statements and all MongoDB queries so that you can see the translation happening.
This ETL application is just one example of how JRuby can help facilitate bridging Java and Ruby based technologies. What interesting solutions are you building with JRuby?